|
1. Accesso multimodale Le
applicazioni multimodali rappresentano la convergenza
di contenuti audio, video, testo ed immagini, con la possibilit� di poter
interagire attraverso diverse modalit� con
l�interfaccia utente. E� possibile
interagire con una applicazione in diversi modi: in input con tastiera, voce, keypad, mouse e penna stylus, e
in output con audio, testo, video, grafici e voce sintetizzata. Il
termine �modale� indica proprio un tipo di meccanismo, un modo per l�input e
l�output di una interfaccia utente. Le
applicazioni multimodali permettono diverse modalit� di interazioni anche simultanee; il browser
dell�utente permette a quest�ultimo di scegliere il
tipo di interazione a seconda della situazione, dell�ambiente di utilizzo o
delle preferenze dell�utente stesso. Per
la realizzazione di applicazioni multimodali
sono necessari un
linguaggio per la progettazione, un browser multimodale, cio�
un interprete in grado di �decifrare� il linguaggio multimodale, un motore Text To Speech
(TTS) che permette di trasformare in voce qualsiasi testo, un Automatic Speech Recognition (ASR) che a partire dalle parole definite in una
grammatica traduce gli input vocali in testo. Il
concetto di accesso multimodale � abbastanza recente,
pertanto non c�� ancora uno linguaggio di riferimento mondiale. A
tal uopo il consorzio W3C ha creato, nel 2002, un gruppo di lavoro, il Multimodal Interaction Working Group
che sta valutando le varie soluzioni proprietarie fino ad oggi sviluppate per
produrre una soluzione unica. In
particolare sono state introdotte le specifiche per un nuovo linguaggio di markup: EMMA (Extensible MultiModal Annotation) che si
propone di estendere il Web per permettere agli utenti di scegliere
dinamicamente il modo di interazione. Per
quanto riguarda invece i linguaggi non standard soluzioni molto interessanti
sono state proposte da Cisco, Microsoft, Intel da un lato e
da IBM, Motorola, Opera Software dall�altro. I
primi hanno introdotto il linguaggio SALT (Speech Application Language Tag) , con lo scopo di abilitare
gli esistenti linguaggi di markup (HTML, XHTML, XML)
all�accesso multimodale e in particolare all�utilizzo della voce nel Web. I
secondi invece hanno inviato al W3C la proposta di standardizzazione
di un linguaggio per il multimodale chiamato XHTML+Voice
(abbreviato X+V) che offre una naturale migrazione
dalle attuali applicazioni voce basate
su VoiceXML o visuali in XHTML ad un�unica
applicazione che sfrutta i vantaggi della voce e dell�interfaccia grafica
contemporaneamente. Il punto di forza di tale linguaggio sta nel fatto che le
pagine HTML o XHTML che attualmente popolano il web
possono essere facilmente convertite in X+V
aggiungendo la parte di parlato in VoiceXML e
inserendo dei tag di sincronizzazione. 2. Il linguaggio XHTML+Voice
Il
linguaggio X+V permette un� interazione
vocale per l�accesso a contenuti web attraverso l�integrazione del gi� maturo linguaggio XHTML e il modulo XML-Events con il linguaggio VoiceXML. Il
linguaggio include moduli vocali che supportano la sintesi vocale, i dialoghi e le grammatiche. I
collegamenti tra elementi di linguaggio vocale e
elementi XHTML rispondono alle specifiche "DOM
Events", quindi l�utilizzo di tali eventi �
familiare agli sviluppatori web. Le
caratteristiche dell�interazione vocale sono integrate in XHTML e in CSS e
quindi possono essere utilizzate in un contesto XHTML.
Il
linguaggio X+V fa parte della famiglia di documenti
XHTML, come specificato nell�"XHTML Modularization". XHTML
� esteso con un modulo che � un sottoinsieme del VoiceXML
2.0, con il modulo XML Events e un modulo che
contiene un piccolo numero di elementi e attributi che
estendono sia XHTML che VoiceXML: il modulo di
estensione XHTML+Voice. Quest�ultimo
modulo facilita lo scambio dei dati di input multimodali tra il dialogo VoiceXML
e gli elementi di input o di testo XHTML. Il
modulo XML Events permette ai
linguaggi XML ospiti di integrare eventi e collegamenti associati a tali
eventi attraverso un�interfaccia DOM2Events. Il
linguaggio VoiceXML � stato progettato per creare
dialoghi audio caratterizzati da parlato sintetizzato, audio digitale,
riconoscimento del parlato e di toni di input DTMF e
registrazione del parlato. Per dar vita al linguaggio X+V
il VoiceXML � stato modularizzato
(cio� � stato suddiviso in moduli ognuno dei quali
contenente un particolare insieme di elementi) ed integrato nella famiglia di
linguaggi XHTML che utilizzano la modularizzazione.
XHTML+Voice � una applicazione XML 1.0
Un
documento X+V per essere conforme deve rispettare le
seguenti regole: 1. Il documento deve essere validato secondo lo schema XML 2. L'elemento radice del documento deve essere
<html> 3. Il nome del namespace
di default deve essere http://www.w3.org/1999/xhtml 4. Se � presente la dichiarazione di un
DOCTYPE e questa include un identificatore
PUBLIC, tale dichiarazione deve far riferimento alla DTD all'indirizzo Ecco
un semplice esempio di una applicazione multimodale in
X+V:
La
prima riga di codice dell'esempio � la solita dichiarazione XML. L'elemento
radice <html> contiene al suo
interno la dichiarazione dei namespaces del
linguaggio. Dovendo convivere pi� linguaggi in una stessa applicazione X+V, la dichiarazione dei namespaces
� necessaria per non confondere eventuali elementi uguali ma di linguaggi
diversi. Poich�
XHTML � il linguaggio che ospita gli altri, il namespace
di default di un documento X+V
� XHTML, mentre per gli altri tre moduli che compongono il linguaggio �
necessaria la dichiarazione di namespaces aggiuntivi:
La
scelta del prefisso che identifica il namespace nel documento � lasciata al programmatore. Nell'esempio sopra il namespace vxml
identifica l'insieme dei tags VoiceXML
utilizzati in X+V, ev definisce il modulo XML
utilizzato per la gestione degli eventi e xv � l'insieme di
elementi necessari alla sincronizzazione delle parti. Nell'
esempio il dialogo con l'identificativo "sayHello" � attivato quando l'user clicca sul paragrafo (tag <p>) denominato "hello".
Tale dialogo � composto da un form
VoiceXML che sintetizza il testo ottenuto dallo
stesso paragrafo che attiva il form. Un dialogo vocale � definito in XHTML+Voice come un form VoiceXML con un unico ID. Il form VoiceXML viene
attivato con un evento del modulo XML Events
attraverso un collegamento nella parte di codice XHTML che si riferisce all�ID
univoco del form. L�evento in questione � generato
dall�interazione dell�utente con un elemento XHTML; eventi del tipo load, unload, click, focus. Una volta attivato il form VoiceXML vengono settate
tutte le variabili del form e degli elementi field in esso contenuti al loro valore iniziale ammesso che
questo sia indicato con l�attributo expr. A questo punto l�interpretazione del codice
all�interno del form prosegue in accordo con le
regole dell�algoritmo FIA che � lo stesso utilizzato
in VoiceXML. Un elemento form VoiceXML richiede informazioni sulla lingua e sulla
versione VoiceXML. In applicazioni VoiceXML 2.0 gli attributi lingua e versione vengono specificati nell�elemento radice <vxml>.
In XHTML+Voice la lingua � ottenuta dall� attributo XHTML dell�elemento radice xml:lang, mentre
la versione VoiceXML viene ricavata dal valore del namespace VoiceXML. La
lingua specificata nell�elemento radice puo� essere sovrascritta
dall�attributo xml:lang nei tags grammar e prompt. In un
documento XHTML+Voice le regole per lo scope
non corrispondono a quelle definite in VXML. I motivi
sono sostanzialmente due; in primis perch� l'elemento
<form> � l'elemento VoiceXML
a livello gerarchico pi� alto in un documento XHTML+Voice,
in secundis perch� X+V non permette le transizioni da un handler
ad un altro. Il
linguaggio VoiceXML 2.0 permette a
un form di essere visibile in un dialogo o in tutto
il documento, ci� non � possibile in XHTML+Voice perch� significherebbe che un form
� attivo mentre se ne esegue un altro e ci� implicherebbe la coesistenza di due
grammatiche attive. Pertanto lo scope di un "form"
e dell'elemento "grammar" � sempre il
dialogo e l'attributo "scope" � ignorato; in particolare se viene processato un attributo scope settato a un valore
diverso da "dialog", il form
non viene invalidato e l'applicazione continua. In
ogni caso quando un documento XHTML+Voice viene processato tutti gli attributi VoiceXML
2.0 che non sono supportati vengono ignorati quando interpretati. Diverso
� il comportamento se il documento X+V contiene
elementi che non sono supportati, ad esempio l�elemento <goto>, in tal
caso infatti viene generato un errore del tipo badfetch e
l'applicazione termina. Questo
significa che un interprete VoiceXML 2.0 e uno X+V possono processare lo stesso codice
VoiceXML se tutti i tags
del codice sono supportati da X+V, mentre non �
necessario che siano supportati tutti gli attributi. XHTML+Voice permette ad un dialogo vocale di essere referenziato come un
collegamento vocale in un file esterno. Poich� il dialogo
vocale non ha visibilit� all�esterno del form, il form nel file
esterno � processato solo quando il form � attivato. Quando il browser carica il corpo di un
documento XHTML+Voice si
genera un evento di �load�. Questo da vita al ciclo di eventi specificato nel modello �DOM Level
2 Events�. Mentre il ciclo degli eventi viene eseguito gli eventi si propagano attraverso l�albero
XHMTL. I
dialoghi vocali,cio� la parte in linguaggio VoiceXML, possono essere interpretati a partire dal codice
XHTML in uno dei seguenti modi:
In
una applicazione multimodale � possibile sia accedere
alla parte vocale in VoiceXML da un elemento XHTML
attraverso degli eventi del modulo XML Events sia
accedere al codice XHTML a partire da un dialogo vocale. In questo
ultimo caso � necessario l�utilizzo di variabili globali JavaScript. Nell�esempio
che segue il valore di un campo di input dal nome �from_city� � settato dal tag VoiceXML �assign� come segue:
In
questo esempio il valore della variabile VoiceXML field denominata �from_field� viene assegnato, attraverso l�elemento assign, alla variabile di input XHTML denominata �from_city�. Ci� �
possibile perch� XHTML+Voice permette ad un dialogo vocale
di condividere la visibilit� con il contenitore XHTML. Quando si verifica
un evento in un dialogo vocale l�autore pu� decidere di terminare il dialogo e
di ritornare alla parte XHTML. XHTML+Voice usa l�elemento VoiceXML <return> a
tal scopo. Tale elemento pu� essere usato anche con gli attributi event e eventexpr
nel caso in cui non ci si trovi ad un livello fondamentale (top-level)
del form vocale. In caso contrario gli attributi vengono ignorati e quando viene interpretato l�elemento si
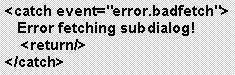
ritorna al contenitore XHTML. Se ad esempio si verifica
un errore nella parte di applicazione vocale e si vuole permettere all�utente
di continuare ad usufruire dell�applicazione interagendo con le sole tecniche
tradizionali si pu� pensare di scrivere una cosa del tipo:
Se invece di �uscire� dalla parte di applicazione vocale si vuole proprio cancellare l�attuale
dialogo vocale nel senso che si vuole forzare il normale svolgimento
dell�algoritmo FIA � necessario l�utilizzo dell�elemento <cancel>. Questo
elemento fa parte del modulo di estensione XHTML+Voice ed � utile perch� nelle applicazioni multimodali non � permesso che pi� dialoghi girino
contemporaneamente sulla stessa macchina. Se un solo dialogo pu� essere
interpretato per volta, l�attivazione di un ulteriore
dialogo deve cancellare l�esecuzione di quello attuale. Inoltre, proprio grazie
all�elemento <cancel> � possibile teminare un dialogo vocale quando il documento XHTML+Voice non � in esecuzione. Un altro importante elemento del modulo di estensione XHTML+Voice �
l�elemento <sync>. Questo permette la
sincronizzazione di elementi di controllo XHTML con
l�elemento VoiceXML <field>. L�elemento
sync fa si che l�input che
viene dato in una modalit� (vocale o visuale) possa settare il corrispettivo
campo dell�altra modalit�. Ad esempio se si riempie un form
attraverso la voce (input vocale) i valori
delle variabili vocali andranno a settare anche
quelle variabili che sarebbero state riempite se si ssarebbe
scelto di interagire con la tastiera. Inoltre se si inserisce
un evento di focus su un elemento <input> che �
sincronizzato con un elemento field VoiceXML l�algoritmo VoiceXML FIA
passa alla esecuzione di quel form. Sync � pertanto sia un messaggio al FIA dal visual browser,
come lo � pure cancel, sia un messaggio dal FIA al
visual browser. Per facilitare il processo di
integrazione tra VoiceXML 2.0 e XHTML � stata
fatta una modularizzazione di VoiceXML
ossia � stato diviso il linguaggio in tanti moduli. Questi moduli non vanno a
modificare le specifiche del linguaggio ma semplicemente organizzano tutti gli
elementi e gli attributi disponibili in VoiceXML in
tanti sottolinguaggi (moduli) in ognuno dei quali �
consentito l'utilizzo di solo alcuni elementi. Poich�
X+V include solo un sottoinsieme di VoiceXML non tutti i moduli definiti in VoiceXML
2.0 sono utilizzabili in X+V. Un elenco di tutti i
moduli VoiceXML con relativa indicazione se fanno
parte o meno dell� XHTML+Voice
� disponibile all�indirizzo: Per
quanto riguarda invece la modularizzazione XHTML essa
si basa sui moduli definiti nella HTML Modularization del W3C. In particolare in X+V sono utilizzabili i moduli definiti in XHTML Basic. Un
elenco dei moduli, degli elementi e degli attributi presenti in tali moduli � disponibile all�indirizzo: Il
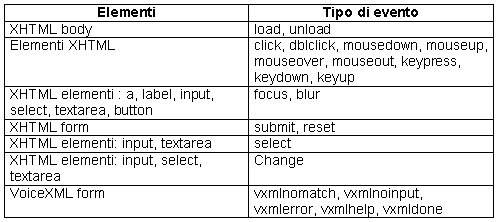
linguaggio X+V estende XHTML con il modulo XML Events. Gli eventi definiti in questo modulo, supportati da
X+V, includono tutti quelli compresi
nelle specifiche HTML 4.01. L'X+V supporta inoltre
gli eventi VoiceXML 2.0 nomatch,
noinput, error and help che in X+V
corrispondono rispettivamente agli eventi vxmlnomatch,
vxmlnoinput, vxmlhelp, and vxmlerror. Gli eventi VoiceXML cancel e exit sono supportati nel form VoiceXML ma non in XHTML.
L'attivazione dell'handler avviene includendo uno di
questi eventi e referenziandolo all'id di un elemento
form VoiceXML. In
aggiunta a questi � stato introdotto l'evento vxmldone
che � generato quando la parte vocale dell'applicazione, legata alla parte
visuale, viene completata. Anche
l'elemento <script> � esteso dal modulo XML Events.
Script di per s� non genera alcun evento ma se viene
correlato dell'attributo "observer" pu�
osservare qualsiasi evento presente nell'albero XHTML e "agire" nel
caso questo evento si verifichi. La
seguente tabella indica gli eventi disponibili in X+V
in relazione agli elementi XHTML o VoiceXML
che supportano tali eventi: Gli
eventi del modulo XML Events in un documento XHTML+Voice si propagano nell'albero XHTML. Il
seguente diagramma mostra come un evento viaggia dal tag
principale HTML al tag target di input
e viceversa. Il flusso di eventi mostrato pu� essere
quello che si avrebbe in risposta ad un click su di un controllo di input da
parte dell'utente. 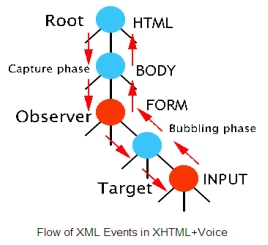
In
questo caso il target dell'evento � un elemento che attiva il form VoiceXML. Il modulo XHTML+Voice
Extension Module estende il
linguaggio X+V con gli elementi <sync> e <cancel>,
l'elemento <prompt> VoiceXML
con gli attributi src e expr e l'elemento <filed>
con l'attributo id. Il
namespace relativo a tale
modulo �: xmlns:xv="http://www.voicexml.org/2002/xhtml+voice" L'elemento
<sync> � necessario alla sincronizzazione di input sia vocali
che visivi. In particolare sincronizza il valore di un elemento di input XHTML con un campo VoiceXML.
Le caratteristiche di questo elemento sono:
E'
bene inoltre sapere che solo le modifiche fatte mentre un form
VoiceXML � attivo sono
sincronizzate. Se viene modificato un preesistente
valore di una variabile di input XHTML e solo successivamente attiviamo l'elemento
VoiceXML <field>, la
sincronizzazione non avviene. Gli
attributi dell'elemento <sync> sono: 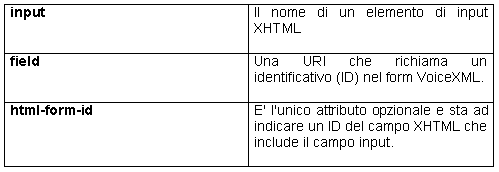
Il secondo elemento del modulo di estensione � l�elemento <cancel>.
Come gi� accennato questo serve a cancellare un dialogo vocale. Gli
attributi dell'elemento <cancel> sono: 
Il
seguente esempio mostra come tale elemento pu� essere
utilizzato per cancellare uno specifico dialogo o quello attuale:
In
questo caso il bottone reset cancella il dialogo identificato da
"fid1" mentre il bottone "Cancella Voce" cancella il
dialogo attuale perch� manca l'attributo "voice-handler". L'
elemento <cancel> di questo modulo � diverso da
quello con lo stesso nome che si usa in VoiceXML, che
invece cancella il prompt che sta girando. L'elemento VoiceXML
<prompt> � esteso con l'attributo src per poter richiamare un testo che deve essere
"letto" dal TTS e che si trova in qualsiasi parte nel documento o
anche fuori del documento stesso. Inoltre �
disponibile l'attributo expr per determinare
dinamicamente un testo, identificato attraverso l'id
dell'elemento <prompt> che lo contiene, che
deve essere letto. L'attributo
src � del tipo URI mentre quello expr � CDATA. 3. Realizzare un'applicazione in XHTML+Voice con IBM Multimodal Tools Come
gi� detto il linguaggio X+V � nato dalla
collaborazione di IBM, Motorola
e Opera Software. Queste
hanno assieme creato anche un potente strumento di sviluppo per la realizzazione
di applicazioni multimodali:
l�IBM Multimodal Tools.
Tale software � dunque proprietario, ma IBM permette, previa registrazione, il download di una versione di prova valida 60 giorni, disponibile al seguente indirizzo: IBM
WebSphere Multimodal Tools � una "espansione" di WebSphere
Studio Application Developer
e/o di WebSphere Studio Site Developer. Attualmente esistono due versioni del Multimodal Tools, a seconda di quale WebSphere
Studio si utilizza: la 4.3.1 per WebSphere Studio
5.1.1 e la pi� recente 4.3.2 per WebSphere Studio
5.1.2. Il
pacchetto Multimodal Tools
comprende:
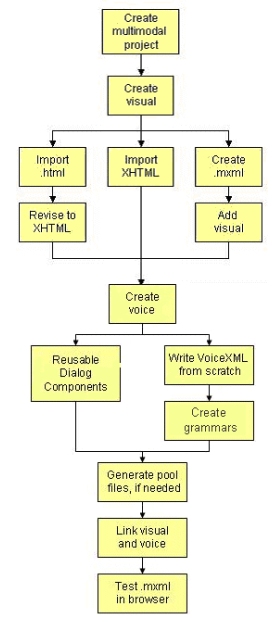
L�algoritmo
da seguire per la realizzazione di una applicazione �
il seguente:
Una
volta installato il Multimodal Toolkit e un Multimodal Browser la prima cosa da fare � creare un
progetto multimodale, ossia una cartella
che conterr� tutti i files dello scenario che si sta
per sviluppare. A questo punto il Multimodal Toolkit da la possibilit� di
editare files mxml, cio� i files che conterranno il corpo dell�applicazione, files SRGS o JSGF per la creazione della grammatica. Il passo successivo � la
creazione della componente video. In X+V il linguaggio che contiene gli altri � l�XHTML pertanto si tratta di inserire codice XHTML
all�interno del file .mxml e in particolare
all�interno dell�elemento <body>. Abbiamo a disposizione sostanzialmente
tre modi di agire:
Per la realizzazione al
punto tre pu� risultare utile l�utilizzo dello
strumento Content Assist che permette di visualizzare
tutti i tags validi che possono essere inseriti nella
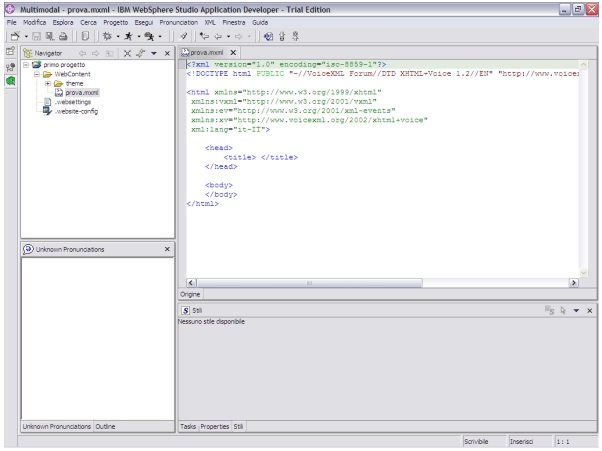
posizione del cursore. Ecco come si presenta l�editor multimodale una volta creato un progetto:
Una volta realizzata la
parte visiva in XHTML si passa
all�inserimento della parte vocale
all�interno del tag <head>. Anche in questo
caso c�� la possibilit� di importare files VoiceXML e di
utilizzare dei dialoghi per scenari comuni che il Multimodal
Toolkit include, oppure di
scrivere la parte di codice e le relative grammatiche attraverso l�editor X+V. Nello scrivere la parte
vocale � necessario la dichiarazione del namespace vxml; se si utilizza l�editor X+V
tutti i namespaces necessari per lo sviluppo di una applicazione multimodale vengono inseriti
automaticamente alla creazione di un nuovo progetto e il prefisso che
identifica il namespace relativo al VoiceXML � per default vxml, pertanto
tutti gli elementi che fanno parte del modulo VoiceXML
devono essere preceduti da tale prefisso. Per quanto riguarda la
creazione delle grammatiche necessarie il Multimodal
Toolkit comprende sia un editor SRGS che uno JSGF. La
scelta di uno dei due linguaggi � del tutto
irrilevante ai fini dell�applicazione e nel caso si preferisce lavorare con un
linguaggio standard qual � SRGS � possibile, usando il conversion wizard, convertire grammatiche JSGF in
SRGS XML automaticamente. Il Multimodal
Toolkit offre inoltre la possibilit� di
personalizzare la pronuncia delle parole all�interno della grammatica creando dei files
di pronuncia e richiamandoli attraverso l�uso dell�elemento <vxml:lexicon>
all�interno del tag <vxml:grammar> . Ogni file di pronuncia che viene
creato pu� essere associato ad una specifica grammatica e tutti i files di
pronuncia devono essere contenuti all�interno della cartella che contiene il
progetto. Una volta completata anche
la parte vocale non resta che collegare la componente
visiva a quella voce e l�applicazione multimodale � pronta per essere
utilizzata. Per fare ci� ci sono sostanzialmente due modi: usare gli elementi
del modulo XML Events oppure usare gli elementi di
sincronizzazione definiti nel modulo di estensione X+V . Nel primo caso basta
utilizzare XML Events Handler,
cio� aggiungere, nella parte XHTML dell�applicazione,
un handler che colleghi la parte visuale con la parte
vocale per mezzo di un evento; il secondo metodo, invece, prevede l�inserimento
di un ulteriore linguaggio che lavora
all�esterno sia della parte XHTML che della parte VoiceXML
e che sincronizza due parti scorrelate. Una volta effettuata la sincronizzazione non resta che testare l�applicazione con un
browser multimodale; nella fattispecie � possibile utilizzare i browsers multimodali Opera e NetFont. Una volta lanciato il
file .mxml sar� possibile vedere all�interno del
browser la parte visuale dell�applicazione e contemporaneamente ascoltare la
parte vocale. Per interagire con la voce � necessario premere un pulsante per
l�attivazione dell�ASR. Questa soluzione pu� risultare
abbastanza antipatica per l�utente ai fini pratici ma � molto utile se si tiene
conto del fatto che cos� facendo l�ASR viene attivato solo quando necessario,
evitando un inutile quanto dannoso spreco di risorse di memoria durante l�uso
dell�applicazione. L�ultimo passo nella
realizzazione di una applicazione multimodale usando
il WebSphere Multimodal Toolkit � la pubblicazione dell�applicazione su di un
server. E� possibile pubblicare l�applicazione su di un test server per
visionare il corretto funzionamento dell�applicazione su di un server. Per fare
la pubblicazione di una applicazione .mxml � necessario creare un progetto dinamico con WebSphere Multimodal Toolkit e poi utilizzare il WebSphere
Application Developer or
Site Developer passando dalla visuale Multimodal a quella Server.
In questo modo � possibile rendere server la macchina su cui si sta
lavorando e provare l�applicazione a tutti gli effetti. |